MapGIS文本大數據分析與挖掘引擎 驅動智能決策的數據處理核心
在當今信息爆炸的時代,文本數據作為非結構化數據的主要載體,蘊含著巨大的價值。MapGIS文本大數據分析與挖掘引擎,作為地理信息科學(GIS)與前沿大數據、人工智能技術深度融合的產物,正以其強大的數據處理能力,成為從海量、多源、異構文本信息中提取知識、發現規律、賦能決策的關鍵引擎。
一、引擎概述:面向空間關聯的智能文本處理
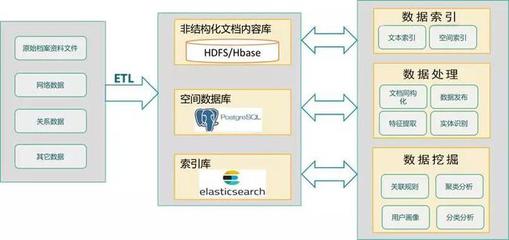
MapGIS文本大數據分析與挖掘引擎并非通用的文本處理工具,而是專門針對與地理空間位置相關聯或隱含空間信息的文本大數據(如社交媒體簽到、新聞報導、行業報告、物聯網傳感器日志等)進行深度處理與挖掘的系統。它構建在分布式計算框架之上,能夠高效處理TB乃至PB級別的文本數據,并通過一系列先進的算法模型,將非結構化的文本轉化為結構化的空間知識,最終與地圖可視化、空間分析等GIS功能無縫集成,實現“數據-信息-知識-決策”的價值閉環。
二、核心數據處理流程與技術
引擎的數據處理流程是一個多階段、智能化的流水線,主要包括以下幾個關鍵環節:
- 多源采集與集成:引擎支持從網絡爬蟲、數據庫、數據倉庫、實時流(如Kafka)、文件系統等多種來源采集文本數據。針對不同來源和格式(如JSON、XML、CSV、純文本等),它提供靈活的數據解析與適配器,確保原始數據能夠高效、準確地匯入處理平臺。
- 數據清洗與標準化:這是提升數據質量的基礎步驟。引擎自動或半自動地進行去重、糾錯、去除無關字符(如HTML標簽)、處理編碼問題等。更重要的是,它能識別并標準化文本中提及的地理實體(如地點名、行政區劃、地標建筑),通過地理編碼技術將其與精準的空間坐標或GIS中的地理要素關聯起來,為后續的空間分析奠定基礎。
- 文本預處理與特征工程:在此階段,引擎運用自然語言處理(NLP)技術對文本進行深度加工。包括:
- 分詞與詞性標注:針對中文等特定語言進行精準切分和語法標記。
- 命名實體識別(NER):不僅識別通用的人名、機構名,更強化對地理位置、地理事件、行業專屬術語等空間與領域實體的識別。
- 情感分析:判斷文本所表達的情感傾向(正面、負面、中性),對于輿情監控、商業評價分析至關重要。
- 關鍵詞與主題提取:利用TF-IDF、TextRank或基于LDA等主題模型,自動抽取出文本的核心關鍵詞和主題分布。
- 向量化表示:將文本轉化為計算機可理解的數值向量,如詞袋模型、Word2Vec、BERT等生成的嵌入向量,這是進行深度挖掘的數學基礎。
- 空間-文本關聯與索引構建:這是引擎的獨特優勢。系統將處理后的文本特征(如主題、情感、實體)與對應的空間位置(點、線、面)進行強關聯,并建立高效的空間-文本聯合索引。這種索引支持諸如“查詢某區域內在過去一周內討論‘新能源汽車’且情緒積極的微博”之類的復雜查詢,極大地提升了檢索與分析的效率。
- 深度分析與挖掘:在高質量數據的基礎上,引擎提供豐富的分析挖掘模型:
- 空間分布分析:分析特定主題或情感文本在地理空間上的聚集、擴散模式(如熱點分析、時空路徑分析)。
- 時空趨勢預測:結合時間序列分析,預測某一地理現象或話題的熱度變化趨勢。
- 關聯規則挖掘:發現文本中隱含的地理事件、要素之間的關聯關系(例如,某類天氣事件常與特定區域的交通擁堵報告同時出現)。
- 分類與聚類:對文本進行自動分類(如區分投訴、咨詢、表揚),或根據內容和空間特征進行聚類,發現潛在的興趣社群或區域模式。
- 知識圖譜構建:將文本中提取的實體(人、地、事、物)及其關系進行結構化,構建具備空間維度的領域知識圖譜,支持智能問答和推理。
- 可視化與成果輸出:處理結果通過MapGIS強大的二三維可視化引擎,以熱力圖、密度圖、軌跡流、統計圖表等多種形式直觀呈現于數字地圖上。分析報告、結構化數據、API接口等多種形式的成果可供其他業務系統調用,支撐規劃決策、應急指揮、商業智能等具體應用。
三、應用價值與前景
MapGIS文本大數據分析與挖掘引擎的數據處理能力,已廣泛應用于智慧城市、自然資源管理、公共安全、交通運輸、商業選址、輿情監控等多個領域。例如,在智慧城市建設中,通過分析市民在社交媒體上的投訴和建議文本,可以精準定位城市管理短板的空間分布;在災害應急中,實時挖掘災區的求救和現場描述文本,能快速評估災情和指導救援資源投放。
隨著多模態學習(融合文本、圖像、視頻)、大語言模型(LLM)以及更實時流處理技術的發展,該引擎的數據處理將更加智能化、情境化和自動化。它不僅停留在“分析已經發生了什么”,更能向“預測即將發生什么”和“建議應該做什么”的更高層次決策支持演進,持續釋放文本大數據中蘊藏的空間智能價值,成為數字孿生和智能化社會不可或缺的基礎設施。
如若轉載,請注明出處:http://www.fjtypd.com/product/46.html
更新時間:2026-02-13 18:29:06