PyTorch數據處理 torch.utils.data模塊的7個核心函數詳解
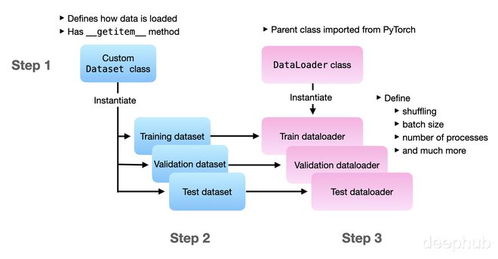
在深度學習中,數據處理是模型訓練和評估的關鍵環節。PyTorch作為一個流行的深度學習框架,提供了強大而靈活的數據處理工具,其中torch.utils.data模塊是核心。它允許我們高效地加載、預處理和批處理數據,從而簡化了訓練流程。本文將詳細介紹torch.utils.data模塊中最重要的7個核心函數及其用法,幫助您掌握PyTorch數據處理的精髓。
1. Dataset
Dataset是一個抽象類,是所有自定義數據集的基礎。它定義了如何獲取單個數據樣本及其標簽。您需要繼承Dataset并實現兩個方法:
<strong>len</strong>(): 返回數據集中的樣本總數。<strong>getitem</strong>(idx): 根據索引idx返回對應的樣本(例如,圖像和標簽)。
示例代碼:`python
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def init(self, data, labels):
self.data = data
self.labels = labels
def len(self):
return len(self.data)
def getitem(self, idx):
return self.data[idx], self.labels[idx]`
2. DataLoader
DataLoader是數據加載的核心工具,它將Dataset包裝成一個可迭代對象,支持自動批處理、打亂數據和多進程加載。主要參數包括:
dataset: 要加載的數據集對象。batch_size: 每個批次的大小。shuffle: 是否在每個epoch打亂數據。num_workers: 用于數據加載的子進程數。
示例代碼:`python
from torch.utils.data import DataLoader
dataloader = DataLoader(dataset, batchsize=32, shuffle=True, numworkers=4)
for batchdata, batchlabels in dataloader:
# 訓練代碼
`
3. random_split
random_split用于將數據集隨機分割為多個子集,常用于劃分訓練集、驗證集和測試集。它接受一個數據集和子集長度的列表,返回多個Subset對象。
示例代碼:`python
from torch.utils.data import random_split
trainsize = int(0.8 * len(dataset))
valsize = len(dataset) - trainsize
traindataset, valdataset = randomsplit(dataset, [trainsize, valsize])`
4. Subset
Subset用于創建數據集的子集,通常與random_split結合使用。它接受一個數據集和索引列表,返回包含指定索引樣本的子集。
示例代碼:`python
from torch.utils.data import Subset
indices = [0, 2, 4] # 選擇索引為0, 2, 4的樣本
subset = Subset(dataset, indices)`
5. ConcatDataset
ConcatDataset用于合并多個數據集,創建一個更大的數據集。這在處理來自不同來源的數據時非常有用。
示例代碼:`python
from torch.utils.data import ConcatDataset
combined_dataset = ConcatDataset([dataset1, dataset2])`
6. WeightedRandomSampler
WeightedRandomSampler是一個采樣器,允許根據權重隨機采樣數據。這對于處理類別不平衡的數據集特別有用,可以為少數類樣本分配更高的權重。
示例代碼:`python
from torch.utils.data import WeightedRandomSampler
weights = [0.1, 0.9] # 假設兩個類別的權重
sampler = WeightedRandomSampler(weights, numsamples=100, replacement=True)
dataloader = DataLoader(dataset, batchsize=32, sampler=sampler)`
7. default_collate
default<em>collate是一個函數,用于將多個樣本組合成一個批次。DataLoader默認使用它來處理批處理。如果您有特殊的數據結構(如變長序列),可以自定義collate</em>fn來覆蓋默認行為。
示例代碼:`python
from torch.utils.data.dataloader import default_collate
def custom_collate(batch):
# 自定義批處理邏輯
return default_collate(batch)
dataloader = DataLoader(dataset, batchsize=32, collatefn=custom_collate)`
###
通過掌握這7個核心函數,您可以高效地處理各種數據場景,從簡單的數據集加載到復雜的批處理和采樣策略。torch.utils.data模塊的設計強調靈活性和可擴展性,使得PyTorch在數據處理方面表現出色。建議在實際項目中多練習這些函數,結合具體需求進行定制化,以提升深度學習工作流的效率。
無論是構建自定義數據集、劃分訓練驗證集,還是處理不平衡數據,這些工具都能為您提供強大的支持。隨著PyTorch版本的更新,該模塊可能會引入更多功能,因此建議關注官方文檔以獲取最新信息。
如若轉載,請注明出處:http://www.fjtypd.com/product/68.html
更新時間:2026-02-13 20:59:03