大數據理論與技術創新 數據處理的演進與突破

在數字時代,大數據已成為驅動社會進步與經濟發展的核心引擎。從理論奠基到技術創新,數據處理作為大數據價值實現的關鍵環節,正經歷著深刻的變革與飛躍。本文將探討大數據理論的發展脈絡,并聚焦于數據處理領域的技術創新,展望其未來趨勢。
一、大數據理論的演進:從概念到范式
大數據理論并非一蹴而就,其發展經歷了從概念萌芽到系統化范式的演進過程。早期,大數據主要被視為數據量的爆炸式增長,“3V”模型(Volume體量、Velocity速度、Variety多樣性)成為其經典定義。理論不斷深化,擴展至“5V”(增加Value價值與Veracity真實性),強調數據的內在質量與潛在效用。
在理論層面,大數據推動了傳統統計與計算范式的革新。例如,采樣理論面臨挑戰,全量數據分析成為可能;因果關系與相關關系的討論日益深入,數據驅動決策逐漸成為主流思維。復雜性科學、信息論等學科與大數據交叉融合,為理解海量、高維、動態的數據系統提供了新的理論框架。這些理論不僅解釋了大數據現象,更指導著技術發展的方向。
二、數據處理技術的創新:架構、算法與工具
數據處理是將原始數據轉化為洞察與價值的過程。隨著數據規模與復雜度的攀升,相關技術持續創新,主要體現在以下幾個方面:
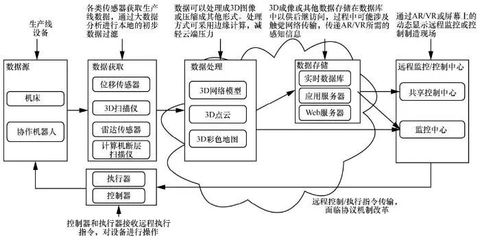
- 計算架構的革新:從集中式的數據倉庫到分布式的處理框架,計算架構的演進是支撐大數據處理的基礎。Apache Hadoop的MapReduce范式開啟了分布式批處理的新時代,而Apache Spark憑借內存計算和DAG執行引擎,顯著提升了迭代計算和實時分析的性能。如今,流處理框架如Apache Flink和Apache Kafka Streams實現了低延遲的實時數據處理,滿足了物聯網、金融風控等場景對即時性的嚴苛要求。云原生與無服務器架構的興起,進一步提供了彈性、可擴展且成本優化的數據處理環境。
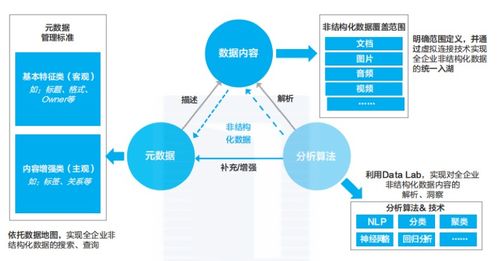
- 存儲與管理的進化:數據存儲從關系型數據庫的單一模式,發展為包括NoSQL(如鍵值存儲、文檔數據庫、列族存儲、圖數據庫)、NewSQL以及數據湖在內的多元化體系。數據湖技術允許以原始格式存儲海量異構數據,實現了存儲與計算的解耦,為后續的靈活分析奠定了基礎。元數據管理、數據目錄和數據治理工具的完善,則確保了數據在復雜管道中的可發現性、可理解性與可信度。
- 處理算法的智能化:傳統的數據處理側重于ETL(抽取、轉換、加載),而現代處理流程日益融入機器學習和人工智能。自動化的特征工程、嵌入式的模型訓練與推理、以及聯邦學習等隱私計算技術,使得數據處理過程不僅能清洗和整合數據,更能直接提取深層模式與智能。例如,在數據清洗階段,可利用機器學習算法自動檢測異常和修復缺失值。
- 工具生態的繁榮:從開源的Apache項目生態(如Hive、Pig、Beam)到商業化的云平臺服務(如AWS Glue、Google Dataflow、Azure Databricks),數據處理工具鏈日益豐富和易用。低代碼/無代碼平臺的出現,降低了數據處理的技術門檻,讓業務分析師也能參與構建數據管道。
三、未來展望:融合、實時與可信
大數據處理技術將朝著更深度的融合、更極致的實時與更堅實的可信方向發展。
- 融合化:批流一體(Unified Batch & Stream Processing)將成為標準,數據湖與數據倉庫的邊界模糊,形成湖倉一體(Lakehouse)架構,兼顧靈活性與性能。數據處理與AI工作流的融合將更加緊密,形成從數據到洞察的自動化閉環。
- 實時化:隨著邊緣計算的普及,數據處理將更多地向數據源頭靠近,實現邊緣智能與實時響應,滿足自動駕駛、工業互聯網等場景的毫秒級決策需求。
- 可信化:數據安全、隱私保護與倫理規范將深度嵌入數據處理全生命周期。差分隱私、同態加密、可信執行環境等技術將得到更廣泛應用,確保數據在流通與利用中的安全合規。
大數據理論與技術創新的核心在于數據處理能力的持續突破。從理解數據的本質到構建高效、智能、可靠的處理系統,這是一場永無止境的探索。隨著量子計算、神經形態計算等新興技術的發展,數據處理或許將迎來又一次范式革命,為解鎖數據宇宙的無窮奧秘開啟新的篇章。唯有不斷推動理論與技術的協同演進,我們才能充分駕馭大數據浪潮,賦能千行百業的數字化轉型與智能化升級。
如若轉載,請注明出處:http://www.fjtypd.com/product/72.html
更新時間:2026-02-13 03:50:41